05 Evaluating
TL;DR¶
flowchart LR
%% Nodes
QS[Quality Scores]
EM[Evaluation Metrics]
FW[Frameworks]
BM[Benchmarks]
RA[Required Abilities]
GT[Ground Truth Data]
SYS[RAG Systems]
%% Edges (functional dependencies)
QS -- quantified_by --> EM
RA -- validated_by --> BM
EM -- implemented_in --> FW
FW -- used_with --> BM
BM -- compare --> SYS
QS -- influence --> RA
EM -- depend_on --> GT
FW -- generate --> GTSam
evaluation | info flow:
-
#5.1-Quality-Scores define what to measure
-
#5.2-Evaluation-Metrics quantify those meanings
-
#5.3-Frameworks implement the measurements
-
#5.4-Benchmarks provide standardized datasets for comparison
-
#5.5-Abilities represent RAG capabilities validated through benchmarks
Use frameworks and evaluation metrics to evaluate the 3 quality scores and 4 abilities. Compare against benchmarks.
Quality Scores (Goals)
-
Context relevance
-
Answer faithfulness
-
Answer relevance
Evaluation Metrics (Formulas)
-
Retrieval Metrics
-
RAG-Specific Metrics (Quality Scores)
Frameworks (Tools)
-
RAGAs
-
ARES
-
TruLens / DeepEval / RAGChecker
-
Ground Truth Generation
Benchmarks (Datasets)
-
Classical QA
-
RAG-Specific
-
Domain-Specific
Required abilities (Properties)
-
Noise robustness
-
Negative rejection
-
Info integration
-
Counterfactual robustness
5.1-Quality-Scores¶
Sam
Definition: Evaluate R & G outputs.
Relations:
-
influences⟶ Frameworks -
depends_on⟶ R & G Components
TrueEra's proposed evaluation (where Q = user query, R = retrieved info/context, G = generated response)
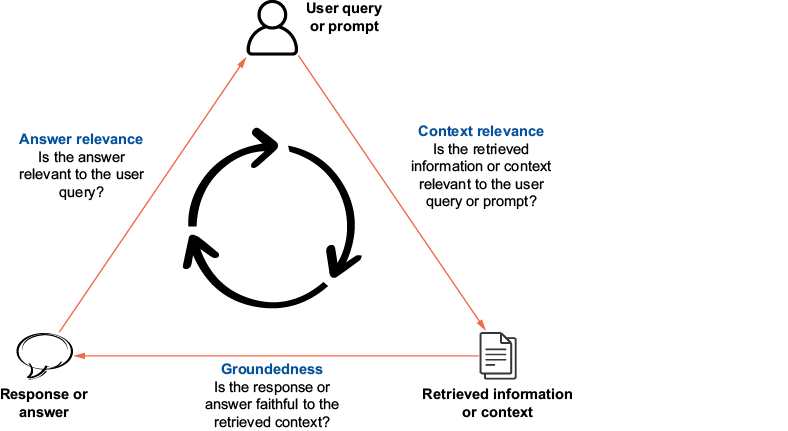{kind=link}
Context Relevance compares
-
(True) Q
-
R
Groundedness (answer faithfulness) compares
-
R
-
G
Answer relevance compares
-
G
-
(True) Q
In greater detail:
Context Relevance
-
Def: Degree of alignment between Q & R.
-
Metrics: Precision, Recall.
-
Evaluated By: Human annotation, semantic similarity, frameworks.
Groundedness (Answer Faithfulness)
-
Def: Degree to which G is factually supported by R.
-
Inverse Metric: Hallucination Rate.
-
Related Metric: Coverage
Answer Relevance
-
Def: How well G addresses Q semantically.
-
Metric Type: Similarity-based
5.2-Evaluation-Metrics¶
Sam
Definition: Quantitative functions measuring RAG performance.
Relations:
-
implemented_in⟶ Frameworks -
used_in⟶ Benchmarks
Sam
2 categories of evaluation metrics
Retrieval Metrics
-
Accuracy: Correct retrieval proportion.
-
Precision: Relevance ratio among retrieved docs.
-
Precision@k: Precision among top-k retrieved results.
-
Recall: Coverage of all relevant docs.
-
F1-Score: Harmonic mean of Precision and Recall.
-
Mean Reciprocal Rank (MRR): Rank position of first relevant result.
-
Mean Average Precision (MAP): Combined precision over multiple cutoff points.
-
nDCG: Rank quality weighted by graded relevance.
RAG-Specific Metrics
-
Context Relevance
-
Answer Faithfulness
-
Hallucination Rate
-
Coverage Score
-
-
Answer Relevance
5.3-Frameworks¶
Sam
Definition: Tools that automate evaluation and data generation.
Relations:
-
implements⟶ Evaluation Metrics -
supports⟶ Ground Truth Generation -
used_with⟶ Benchmarks
Subclasses:
-
RAGAs
-
ARES
-
Others: TruLens, DeepEval, RAGChecker
5.4-Benchmarks¶
Sam
Definition: Standardized datasets and tasks to compare RAG systems.
Subclasses:
-
Classical: SQuAD, HotpotQA, BEIR
-
RAG-Specific
-
RGB: For noise robustness, negative rejection, counterfactual robustness.
-
Multi-hop RAG: For multi-document reasoning. (Inference, Comparison, Temporal, Null queries).
-
CRAG: For factual QA with diverse question types
-
5.5-Abilities¶
Sam
Definition: Functional capacities that determine robustness and utility of RAG systems.
Subclasses:
- *Noise Robustness*: Can ignore irrelevant docs. (*Relates to R.*)
- *Negative Rejection*: Can respond “I don’t know” when facing insufficient context. (*Relates to G.*)
- *Information Integration*: Can synthesize multiple sources.
- *Counterfactual Robustness*: Can reject incorrect/contradictory context.
Additional required abilities: Latency, Bias & Toxicity, Robustness