Snowflake
Systems-Thinking Model¶
| Layer | Guiding Question | Snowflake |
|---|---|---|
| Purpose | Why does this system exist? | Enable scalable, cloud-native data warehousing |
| Capabilities | What does it do? | Store / query / share massive datasets |
| Mechanisms | How does it achieve that? | Elastic compute, separation of storage/compute |
| Architecture | How are parts organized? | Layers (Cloud Services ⟶ Compute ⟶ Storage) |
| Components | What are the concrete parts? | VWs, Metadata Services, etc. |
Snowflake Overview¶
Resources
Key Terms:
-
VWs (virtual warehouses): Independent compute clusters that execute SQL queries, load data, and run transformations.
-
Architectures: Overall design of Snowflake. Separates & orchestrates core subsystems.
-
Layers: The core subsystems.
- Components: The concrete building blocks inside each layer.
-
Snowflake:
-
Supported workloads: ML / streaming analytics / BI / unstructured data processing
-
Integrations: Tableau, Fivetran, APIs
-
Hosted on: AWS
Over time:
-
2020: Snowpark (framework) for data pipelines (SQL/Python)
-
2021: Unistore (workload) combines transactional & analytical operations within 1 platform
-
2023: Native App (framework) to build / distribute / monetize apps that run securely within Snowflake
-
2024: Cortex (genAI services) embedded into the platform.
Notes¶
1. Purpose¶
-
Now: Lots of manual "glue" code from FiveTran ⟶ postgres ⟶ SQL queries ⟶ Tableau.
-
Snowflake: Unified single platform. Store ⟶ query ⟶ share.
2. Capabilities¶
In essence: Snowflake’s capabilities let you store once, query anywhere, scale automatically, and share securely.
Core 3 categories:
-
Storage: Centralizes data from Fivetran + postgres.
-
Compute / Processing: Replaces postgres-based analytics processing
-
Share: Share across accounts/clouds. Reduces duplication.
3. Mechanisms¶
In essence: Snowflake achieves its capabilities by decoupling storage/compute, automating scaling/optimization, and using rich metadata to prune and share data efficiently.
-
Decoupling storage/compute: Independent subsystems ⟶ flexibility/scale.
-
Automating scaling/optimization: Auto-scale/multi-cluster warehouses, auto-clustering, compression, statistics collection, result caching, managed replication.
-
Uses rich metadata: Micro-partition stats enable aggressive pruning; time travel/clone are metadata pointers; secure sharing exposes metadata, not raw copies.
4. Architecture¶
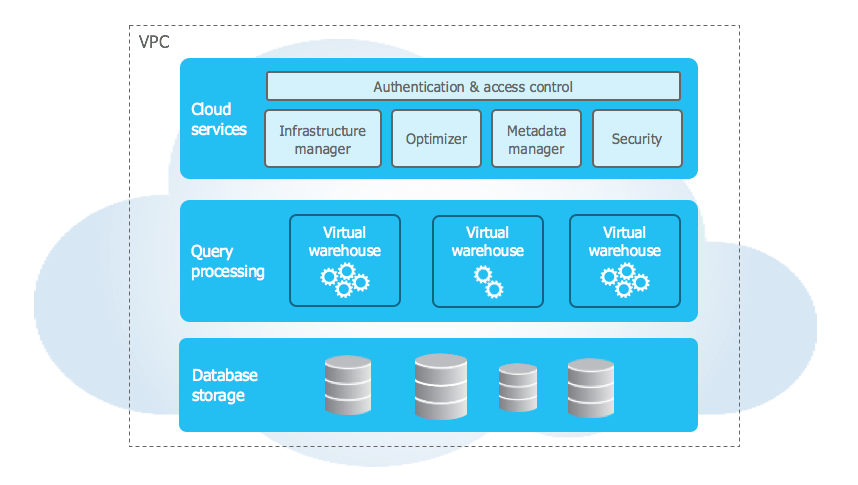{kind=link}
Snowflake’s architecture is a 3-layer system: Storage, Compute, and Cloud Services.
3 layers
-
Storage: In cloud DBs (schemas ⟶ tables/views)
-
Compute / Processing: Via virtual warehouses
-
Cloud Services: Coordination (security, optimization, sharing).
5. Components¶
Within the 3 layers:
-
Storage layer components:
- Databases ⟶ Schemas ⟶ Tables/Views ⟶ Micro-partitions
-
Compute / Processing layer components :
-
Virtual Warehouses
-
Resource Monitors
-
-
Services layer components:
-
Catalog/Optimizer/Transactions (services layer)
-
RBAC (Roles, Grants), Network Policies
-
Policies: Masking, Row Access, Tags/Classification
-
Search Optimization Service (point-lookups), Query Acceleration Service (optional)
-
Other components:
-
For Ingestion/Integration
-
Fivetran connectors ⟶ use COPY or Snowpipe (auto-ingest)
-
After-Fivetran transforms ⟶ Streams (change capture) + Tasks (scheduled ELT)
-
Postgres as source via Fivetran or External Tables
-
-
For Dev
-
SQL + UDFs
-
Snowpark (Python)
-
-
For Tableau
-
ODBC/JDBC/Snowflake connector ⟶ each Tableau project uses its own warehouse
-
Views for dashboards
-